
05 — SPECIALIZATION
LoRAs & Embeddings: Fine-Tuning the Model’s Personality
Base checkpoints are generalists. LoRAs (Low-Rank Adaptation files) are specialists. A LoRA is a small auxiliary model — typically 50–200MB — that was trained on top of a base checkpoint to inject a specific style, subject, or concept into the generation process.
Rather than retraining the entire model from scratch (a process requiring weeks and significant hardware), LoRAs inject small, targeted weight modifications into the existing model at inference time. You might load a LoRA trained on a specific artist’s brushwork, a particular character’s likeness, a specific lighting style, or a product design aesthetic. Multiple LoRAs can be stacked simultaneously, each with its own strength value controlling how much influence it exerts.
Textual Inversions (also called embeddings) work differently — they operate at the CLIP level, teaching the text encoder a new “word” that maps to a complex visual concept. Instead of modifying model weights, they add a new token to the vocabulary. You invoke them directly in your prompts. Common uses include style descriptors, quality boosters, or specific aesthetic fingerprints.
06 — THE CORE
The Sampler: Where Images Are Actually Born
The sampler is the heart of the entire pipeline. This is where the diffusion process takes place — where noise becomes an image, step by deliberate step.
At step zero, you have pure noise. At each subsequent step, the neural network makes a prediction: given the current noisy state and the text conditioning, what would this look like if it were slightly less noisy? A small amount of noise is removed, and the result is fractionally more coherent. Repeat this process dozens of times, and a recognizable image gradually emerges.
KEY PARAMETERS:
Steps — Number of denoising iterations. 20–30 is typical; more steps refine detail but with diminishing returns beyond ~40 for most samplers.
CFG Scale — How strictly the model follows your prompt. 1.0 = ignores prompt; 7–12 = strong adherence; 15+ often causes oversaturation and artifacts.
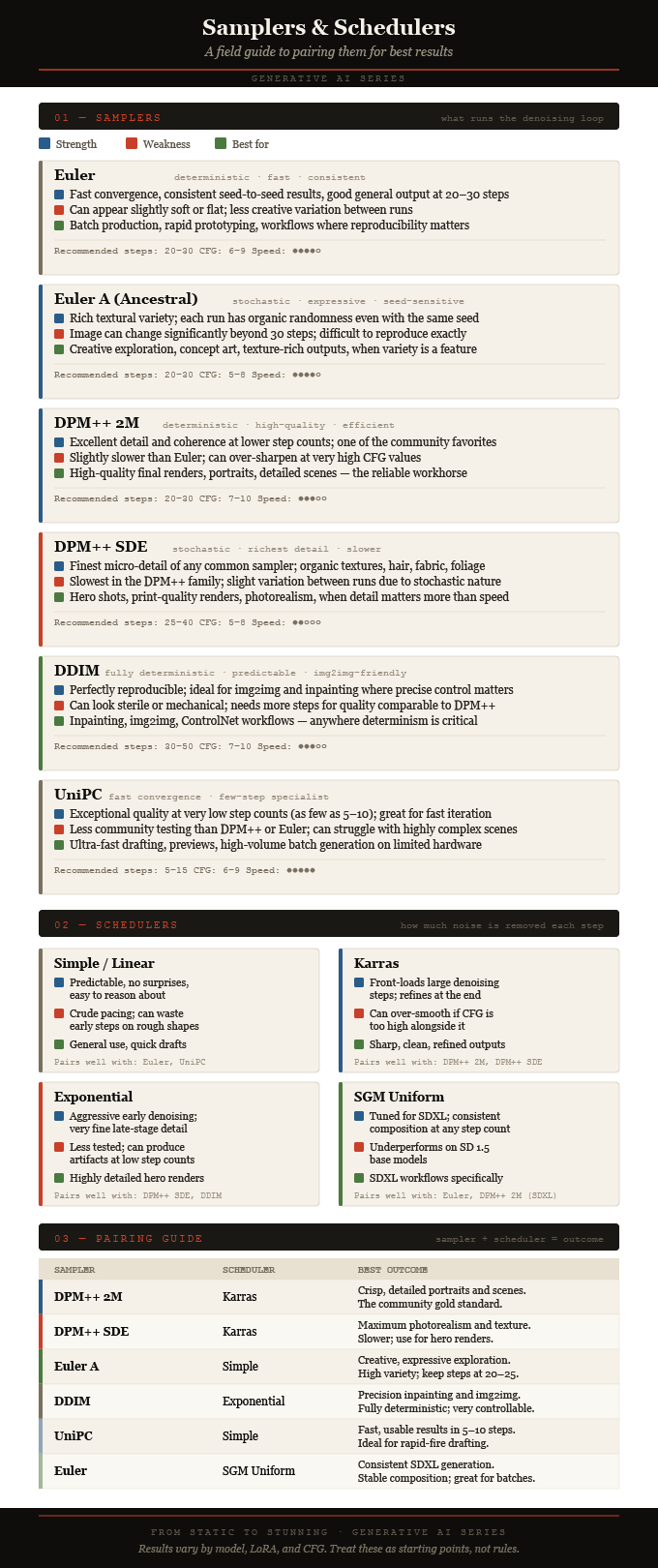
Sampler — The algorithm used to remove noise each step. Options like DPM++ SDE, Euler A, and DDIM each produce different aesthetic characteristics.
Scheduler — Controls the pacing — how much noise is removed at each step. Karras and Exponential schedules often produce cleaner results than linear ones.
Denoise — 1.0 = start from pure noise (full generation). Values below 1.0 are used in image-to-image workflows, where you partially redraw an existing image.
The CFG scale deserves special attention. It controls the tension between creativity and instruction-following. Low CFG values allow the model to make more autonomous aesthetic decisions; high values force it to adhere rigidly to your prompt. The sweet spot varies by model — some newer architectures perform best at surprisingly low CFG values (as low as 2.0), while older models typically needed 7–12 for good prompt adherence.
The sampler algorithm itself matters enormously. DPM++ SDE (Stochastic Differential Equation) produces rich, detailed outputs but can vary slightly between runs due to its stochastic nature. Euler A is fast and creative but less consistent. DDIM is fully deterministic, producing identical results for identical seeds. Each sampler is essentially a different mathematical strategy for navigating from noise to image.
07 — RESOLUTION
VAE Decode: Returning to the World of Pixels
Once the sampler completes its final denoising step, the result is still a latent tensor — a compact mathematical representation, not a viewable image. The VAE decoder takes this latent and expands it back to full pixel resolution, reconstructing the RGB image your eye can finally see.
This decoding step is not lossless — the VAE makes interpretive decisions about fine-grain texture and micro-detail. A higher-quality VAE will render sharper edges, more accurate colors, and better fine detail in areas like hair, fabric, and text. For this reason, swapping the default VAE for a community-improved version is one of the most impactful low-effort improvements you can make to any generation workflow.
08 — GOING FURTHER
ControlNet, Upscalers & Beyond
The core pipeline above produces excellent results, but the broader ecosystem extends it significantly. ControlNet adds spatial guidance — you can feed in a depth map, a pose skeleton extracted from a reference photo, or an edge-detection image to constrain the composition of your output rather than just its content. Instead of hoping the model places your subject in the right position, you can precisely dictate it.
Upscalers address the resolution ceiling of base models. Tools like ESRGAN and Real-ESRGAN use separate neural networks trained specifically on super-resolution tasks to enlarge a 512px output to 2048px or beyond, adding believable fine detail in the process. Latent upscaling takes a different approach, re-running the diffusion process at higher resolution to generate new detail rather than interpolating it.
IP-Adapter nodes allow you to feed reference images directly into the conditioning process — influencing the style or subject of the output from a visual example rather than purely from text. Inpainting applies masked diffusion to specific regions of an existing image, regenerating only selected areas while preserving the rest. These tools transform the basic text-to-image pipeline into a full creative suite capable of extraordinary precision.
09 — THE WHOLE PICTURE
Noise, Mathematics, and the Art of Guided Chaos
Strip away all the terminology and the pipeline tells a simple story: you begin with chaos, you describe order, and a neural network — trained on an incomprehensibly large body of human visual culture — iteratively bridges the gap between them.
Your words become vectors. Your blank canvas begins as static. A sampler algorithm navigates probabilistic space, step by step, removing noise and adding coherence until meaning crystallizes from randomness. A decoder translates the result back into something your eyes can read. And then, in the span of a few seconds, an image exists that has never existed before.
Every AI image is a collaboration between human language, compressed visual memory, and the mathematics of guided noise — a sculpture revealed from randomness, one denoising step at a time.
Understanding this pipeline doesn’t diminish the magic — it deepens it. When you know what a sampler is doing, you can choose the right one. When you understand CFG, you can tune it deliberately. When you know how LoRAs inject their influence, you can stack them thoughtfully. The tools become extensions of your creative intention rather than black boxes producing unpredictable results.
That’s the real power of understanding how AI generates images: not just appreciation, but mastery.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
From Static to Stunning · Generative AI Series